The following is a comparison of economic rationality and Null Hypothesis Significance Testing from the perspective of the former. The starting point is maximization of expected utility, which is a standard criterion for economic rationality. Then the focus is on the ingredients in economic rationality that must be thrown away to end up with NHST.
1. Decision theory and economic rationality
Consider a simple situation where there are two mutually exclusive hypotheses that we call 










The standard criterion in decision theory and economics is to choose the action that maximizes the expected utility. In the present simple setting this means comparing the expected utilities
If 


One could stop the exposition of decision theory here, on the note that decision theorists take into account both probabilities and utilities when choosing how to act. However, to better connect to standard statistics, it is useful to also consider the situation after new data becomes available. Once new data 



Next, assume for simplicity that the new data does not affect the utilities. In symbols, 


1.1 Reduction to three parameters
Utilities lack scale in the sense that two utility functions that just differ by constant shift are equivalent. Moreover, two utilities that differ by a constant factor are also equivalent. This can be exploited to reduce the number of parameters that need to be considered when choosing between the actions.
To check whether 
is positive or negative. In this difference any constant shift of utilities cancels out, which may be emphasized by introducing two relative utilities
In terms of these relative utilities,




Next, the lack of multiplicative scale can be exploited. Because 


we may note that 


As a final touch, since we only care about whether 

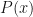


In the final expression above, the Bayes factor or likelihood ratio has been introduced:

An economically rational agent can thus choose action by checking whether 




where the right-hand side can be computed before the data

2. The Neyman-Pearson school
To go from decision theory and economic rationality to Neyman–Pearson’s framework is almost as easy as these two steps:
- Step 1: Forget about prior knowledge and the probabilities
- Step 2: Relegate the utilities to a background role, but do not completely forget them.
The philosophy behind Step 1 is that prior probabilities of hypotheses are too subjective to have a place in statistical reasoning. On the other hand, the likelihood 
In the section on decision theory, it was not necessary to assume much about the actions. In Neyman–Pearson’s framework, the action 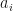


In the Neyman–Pearson framework, the ideal decision criterion is a likelihood ratio test. In such a test, one chooses a threshold 


then this procedure is equivalent to the economically rational criterion. However, in Neyman–Pearson’s framework one does not aim to be economically rational. Instead, one aims to find a good trade off between Type I and Type II errors. The likelihood of a Type I error is denoted
and is called the significance level. The likelihood of a Type II error is written
and 

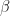



2.1 Filter data
There is an optional third step:
- Step 3: Replace the likelihood ratio by a suboptimal statistic.
A statistic is a quantity that summarizes the data 
The test statistic should mimic the feature of the likelihood ratio that large values are more compatible with 


The choice of statistic 


3. Null Hypothesis Significance Testing
Step 3 was optional above. In Null Hypothesis Significance Testing (NHST), Step 3 is mandatory. Additionally:
- Step 4: Forget all about the costs of Type I and II errors.
- Step 5: Forget about the likelihood
.
In NHST, prior knowledge and utilities are disregarded and decisions are made based on only the likelihood 

Deviating slightly from the notation in previous sections, let’s denote the actually observed data by 


Checking whether

Since
- Step 6: Let the actions be “reject
“Not reject
3.1 Why rely on NHST?
NHST is flawed enough that one may wonder why it is so popular. Many articles linked in previous posts on this blog have commented on this. I also found two recent articles devoted to this question:
- J. Stunt et al. Why we habitually engage in null-hypothesis significance testing: A qualitative study. Plos ONE (2021), https://doi.org/10.1371/journal.pone.0258330
- G. Gigerenzer. Statistical Rituals: The Replication Delusion and How We Got There. Advances in Methods and Practices in Psychological Science (2018), https://doi.org/10.1177/2515245918771329
